
Once I was working in the software development company. It was a regular company: nothing really bad, but nothing fancy. It had the same problems as other similar companies:
- Low-quality code
- Unmet deadlines
- Budget overflows
And disappointed clients as a final result.
Of course, everyone in management was eager to know, what (or “who”) was the reason. During our workday, it was quite normal to hear something like: “the project is failed because you wrote low-quality code, now the client is moving away from us”.
Did it help in any way? No. Was it pleasant to work there? No. So, once I woke up and decided that I do not want to work in this company anymore.
The ugliest part is that I was the founder of this company.
Can we please all agree that blaming does not work?
Before going any further and describing how we did manage to change our environment and how it did affect our results, I would like to point it straight: blaming someone for anything does not work. Why?
- It indicates broken processes exist inside the company’s workflow, but instead of fixing them people just point fingers and completely hide the problem. So, it will never be fixed
- It demotivates people. You can lose the best engineers because of that. There are companies where people behave differently. And we, engineers, can choose
What can we do instead? We can build our processes another way!
Improve your project instead of blaming anyone
Can you imagine a situation when something goes wrong? When your production stopped working because there was a dependency version mismatch. Or because you made a silly typo in your string variable.
That happens quite often, that’s not a surprise.

So, we must be ready to handle that. We must create a working set of rules and practices to dodge possible errors and handle the ones that we failed to detect early.
But how?
Small tasks and clear scopes
It usually hard to define big tasks that take days and weeks. This kind of tasks does not have a clear scope and “done” criteria.
So, that’s where things can go wrong. Two people will understand these task differently because of this wider scope. They will prioritize different of the task parts differently. And in the end, it will be easy to say: “You did a bad job, you did not get the task”.
Moreover, it will be hard to review and control the quality of the code. We all know how hard it is to review 1000+ lines of code.

I insist that task should be small (not bigger than 4 hours) and should have a clear scope. It is better to have five small and clearly defined tasks than one big task.

This decreases the possibility of misinterpretation. And allows both sides to track progress easily, control deadlines, and feel the pulse of the project.
Make your CI as strict as possible
The sooner you find errors in your code the better it is for the project. This graph illustrates how expensive (in terms of time and money) it is to allow the bug to flow into the production.
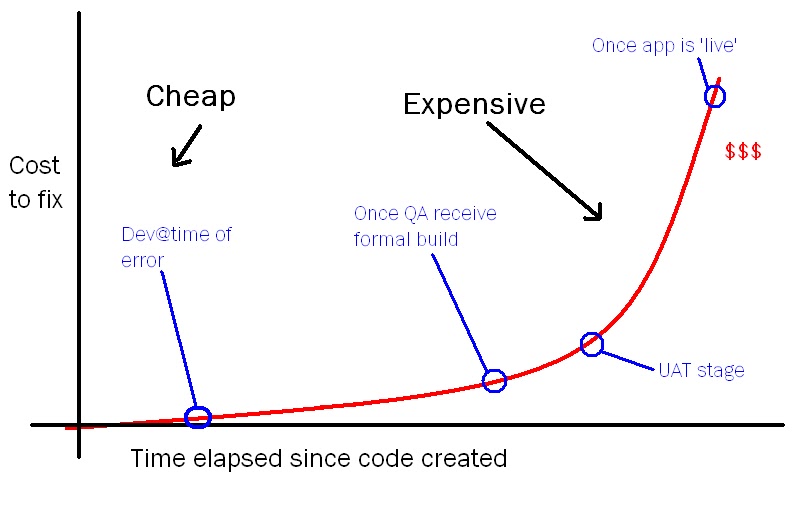
Bad code should not reach master branch and even a human reviewer. And we can automate that! There’s static analysis, linting, different kind of tests and other metrics that should pass before. If something is broken - your code just won’t make its way to the master branch and reviewer won’t review it until all checks pass.
This way creates clear and transparent quality rules that should be met. That’s become a law.
Welcome all bugs
But errors will still happen! That’s a sad reality. But it is your choice how to treat them. You can get angry and depressed because of them, or you can learn from them.
I prefer to learn from my and others mistakes. How is that possible?
Whenever something bad happens in production you need to track how your quality gates allowed this to happen. What did we miss?
After your team finds the answer - you should automate this check to be sure the next time it won’t happen again. Create a linting rule or write a regression test.
Here are some real world examples of how we do that.
Whenever something bad happens for our python/django project we add a new rule to the CI process or write a new linting rule for our corporate linter. This way we guaranty, that this won’t happen again.
And the same works for our frontend javascript/vue projects.
Make your client a part of the process
There are cases when you can lose your client not because your code is bad, but because you failed in building a clear communication channel with your client. And then you will be blamed for all of the bad things!
We had a lot of problems with that in the past. Long iterations and long feedback cycles were killing us. We failed to address bugs and new requirements fast enough.
The answer to this problem is simple:
- Make your client a part of your development process
- Make your iterations as small as possible
- Demonstrate your progress as frequently as possible
We achieve all these goals by several useful practices:
- We invite our clients to the repository from the first day
- Microtasking allows us to make several iterations in a single working day
- Gitlab and K8S allow us to make the demo of each individual feature when needed
We collect feedback from the client as soon as we can. The client always understands what is going on in the project: what is done and what is work-in-progress.
This way it is hard and pointless to blame anyone, collaborate and build awesome products together. In the end, that is the goal we pursue, isn’t it?
Conclusion
“No blaming, but fixing” method drastically changed how we work in a good way.
Since we practice these things we have not failed a single project. And we have not lost a single engineer because of the conflict.
Of course, this article does not cover all features and tricks that we use in our daily life, but you can read more about how we work at the RSDP (Repeatable Software Development Process) home page. And you can follow me on github to be informed about what tools we build.