There are some basic engineering practices that I want to cover with a series of posts starting with the most important one: how to fix a bug?
First, why do I think that fixing bugs is the most important thing? Because bugs happen all the time. If you write code, you write bugs. And that’s not a problem at all. Repeatable Software Development Process, that we stick to, works on that basis: people make mistakes. I wrote an article about it not so long ago: developer should not be blamed for bugs, the project should be.
The important thing is: how do you respond to the bugs you and other people have created? What do you do to prevent them from happening in the future? How do you even know that this buggy situation even exist?
Spotting a bug
Before you can actually fix something, you need to spot the incorrect behavior. And it might be tricky. Consider these two cases:
- All users cannot log in into the account because of an error.
- Exactly one user is facing a strange behavior of your app on a local machine from time to time.
Which one will be easier to spot? I guess you have guessed right: the first one. Some bugs are more visible than the others.

There are several factors that affect the discoverability of the bug:
- How many users are affected by this bug? If the number is large enough, someone will definitely tell about it. Is it reasonable to use your users as a monitoring service? That’s another question we won’t discuss in this article.
- Where the code is executed? On your server it is much easier to create a monitoring service that will catch most of the unexpected things and alert you about it. Sometimes you don’t have access to the product you have created. For example, when it is shipped to corporate clients that use their own infrastructure. It is also much easier to create a fixed environment so any third-party entities won’t mess around with your project.
- How hard it is to reproduce? Some bugs are easy to reproduce. Click this link, type this text, hit enter. Some bugs are insane! You need to set up a special environment, install some specific software, perform strange actions, and then you will reproduce the bug (with some luck on your side). It is important to mention that some bugs are just not reproducible at all. They can just be ignored.
Of course, there are tools to help you to spot bugs and alert you when they happen.
- Sentry helps you to track errors from your code. It supports almost any language and there is a free self-hosted version. It also allows collecting direct verbal feedback from your users.
-
Prometheus is one of the most popular monitoring tools. It is available via
docker-compose upto jump start. - There are also paid services like
NewRelic,Wombat,DataDog, and many others.
Lifehack: you can start with just Sentry it will cover most of your needs with the simplest setup. You can add more services and tools when you will need them.
Reporting a bug
Once the bug is spotted, it needs to be reported. Seems like an easy step, doesn’t it? Well, actually, it may seem easy, but it is for sure the most important part of the process. To report a good bug you will need to submit a lot of information. Your issue must tell a story:
- Why do you think that this is a bug? Maybe this is a feature…
- What should happen in your opinion? Bugs without a clearly defined expected behavior can become really hard to fix. And they can grow to feature requests. Which should be solved differently.
- Why this bug is important? You have to prove that it should be fixed right now. Since some bugs are trifling and can be ignored for now.
- How to reproduce an issue? This should contain all the technical information about the issue. What versions were used? What browser / OS is used? What configuration is applied? Sometimes it is even possible to create a separate repository just to show an issue reproduction.
- Where to look for extra information about what happens: logs, stack traces, screenshots, monitoring reports, required input data, related bugs, and features, etc. All links must be present in the submission. Otherwise, it would be really hard to solve this issue when the time pass.
Lifehack: screenshots and gifs rock for systems with UI! Try to use them as frequently as you can. But, never use screenshots to capture text information from stack traces and debug output, since it can not be copied by other developers.
Now, let’s have a look at two examples of different bugs created in the same project. First one is strict about versions, traceback, scope. It is a good bug report.
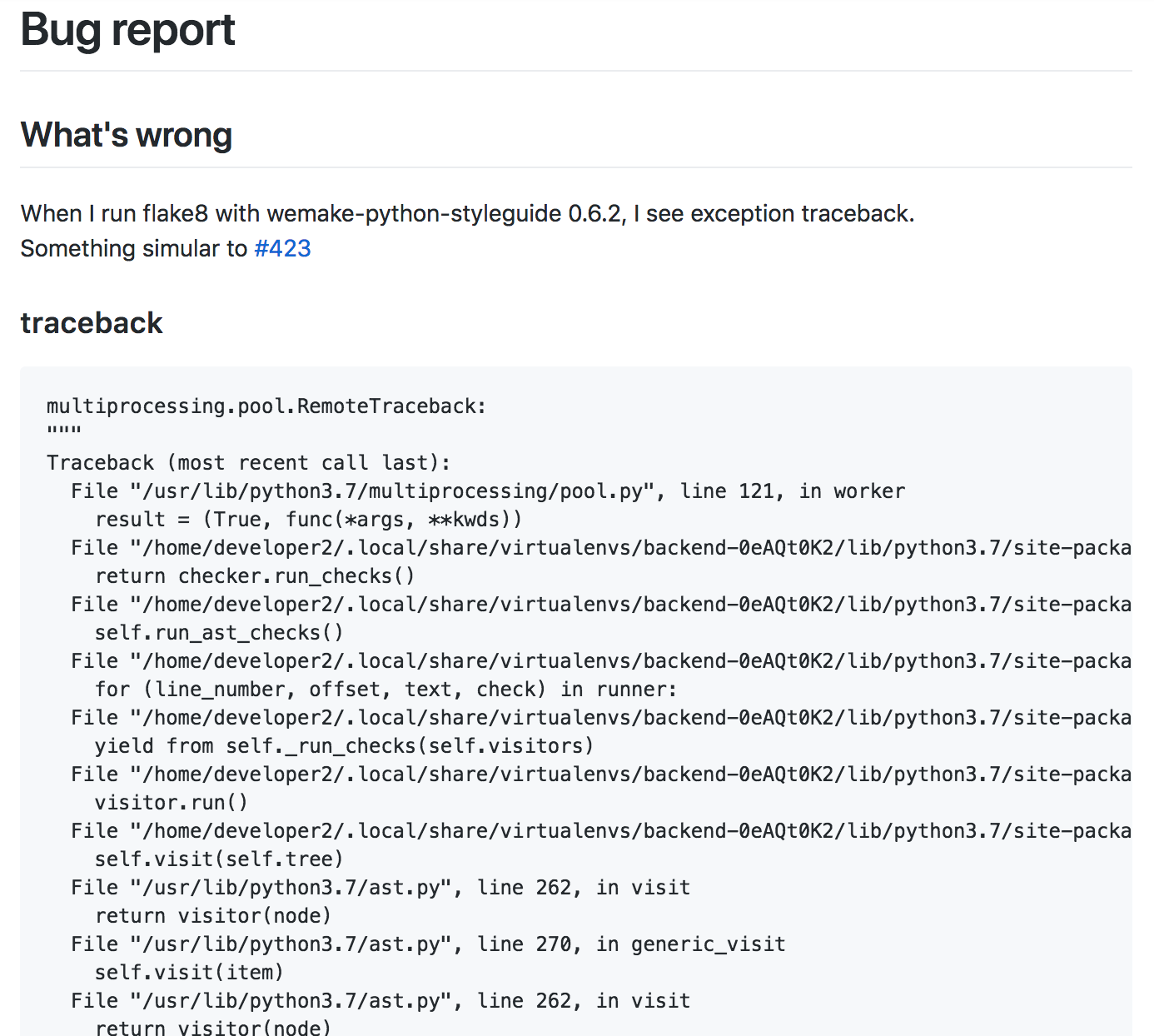
The second one was reported by me. It is a bad example of the bug report.

It violates almost all rules we have defined previously. It was made in a hurry - not to forget about this ticket after I had a cellphone conversation with one of my users. Do not do this.
Here are some real-world bug report templates that you can use in your projects:
There’s also a collection of different bug templates in github-issue-templates repo. Feel free to use any of them to make your development process better!
Reproducing a bug
Now, you will need to reproduce this bug. And not just with your hand, but with your code. Remember - your goal is not to have the same error once again. How is that possible?
You will need to write a regression test that will fail. It might be a unit or E2E test, it does not matter. This is just a test that is failing and exposing the bug you are trying to solve.
Lifehack: sometimes you might want to submit a broken code to your branch so it will trigger a CI build. After the build, it will be saved in your project. And your colleagues will be able to link to this problem. Your next commit will have to solve the issue.

What instruments help you to reproduce complex bugs? Well, there are a couple of them:
- A debugger is your best friend in all cases.
- Finding concurrency bugs is hard, and sometimes even harder to reproduce. In this case, you can fall back to static analysis and use it find your bugs statically.
- Sometimes you might need to tweak your infrastructure, that’s where infrastructure-as-code comes in handy.
Remember, that some bugs cannot be reproduced in a reasonable amount of time.
You can have a look at some regression tests I have created for wemake-python-styleguide. Here’s a sneak peak of a test structure that works for us:
code_that_breaks = '''
def current_session(
telegram_id: int,
for_update: bool = True,
) -> TelegramSession:
...
'''
def test_regression112(default_options):
"""
There was a conflict between ``pyflakes`` and our plugin.
We were fighting for ``parent`` property.
Now we use a custom prefix.
See: https://github.com/wemake-services/wemake-python-styleguide/issues/112
"""
...
# It was failing on this line:
# AttributeError: 'ExceptHandler' object has no attribute 'depth'
flakes = PyFlakesChecker(module)
assert flakes.root
Fixing a bug
Now when we have our bug spotted, reported, and reproduced we have to actually fix it.
That’s the part when you actually modify your codebase to remove the unexpected behavior. That should not be that hard after all!
After you fixed your code and submitted your code, CI build must pass. If so, the bug is fixed. But, there’s one more thing to do.
Wait, what?
Yes, there’s one more thing that most developers tend not to do: writing a postmortem. Some bugs are really easy and do not require this step, but some bugs cost us a lot of time and money. We should take extra care about them. Postmortem is a non-technical story of what had happened that you can show to your management (and the one they will understand). What should be included in a postmortem?
- Why did the bug happen? This must be a non-technical summary of all actions that lead to this problem. And it must contain a link to the original bug report.
- What have we done to fix the bug? Again, keep it simple, do not go deep into technical details. Just make sure that your commit is linked to this document.
- What impact it had on our product/users/clients? It needs to be calculated or intelligently guessed.
- What was the timeline? Remember when you saved all links to the logs/monitoring/ etc? It will be useful to build a timeline. How long we had suffered from this bug? When did it get solved?
That’s why postmortem is required: it will tell a story about this bug to the future team. Keeping a consistent list of most important bugs will drastically improve your project’s documentation. And as always here’s a link to different postmortem templates.
Afterword
That’s how bugs are fixed by high-skilled engineers. Some implementation may vary, but the principle always remains the same: discovery, reporting, reproduction, fixing, documenting.
I hope this article will help your project to grow. Subscribe to my github account if you want to know what instruments for developers I am building at the moment.